
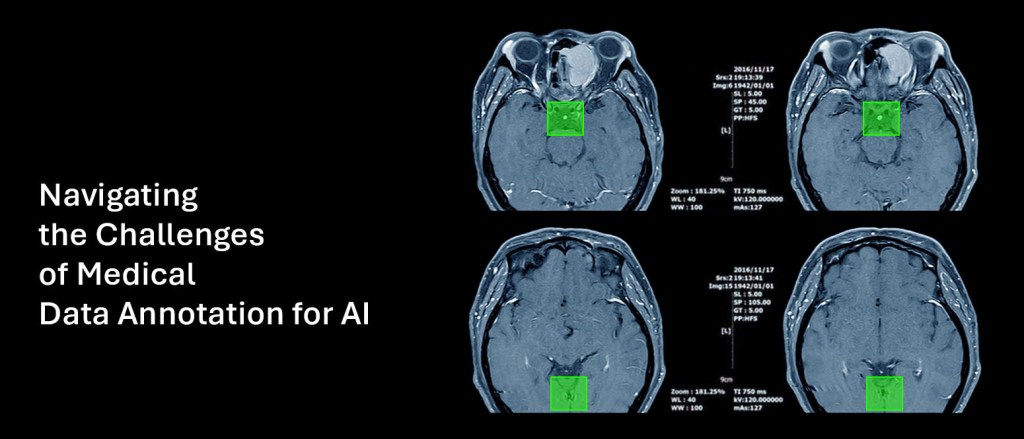
Image annotation is the only technique helps machine learning or AI-based perception model to recognize the particular object in an image and learn to detect the such objects when used in real-life. And there are different types of image annotations, like polygon, polylines, landmark, semantic segmentation and bounding box which is one the most common image annotation technique used to make the objects recognizable into 2D and 3D formats.
Difference Between 2D and 3D Image Annotation
2D Image annotation includes both labeling of the whole image and labelling all pixels, In such annotations of multiple similar images can be simplified when the dataset is clustered based on a visual similarity measure, allowing the user to link labels to clusters instead of going individually through all images.
2D and 3D images annotations done as per the project’s requirements, in self-driving model training, 3D annotated images are more helpful and gives a more precise perception of an objects, while in various sector like retail and automated farming, 2D annotated images are also enough to allow machines detect the objects for future prediction.
How 2D and 3D Images are Annotated?
In 2D image annotation, a line is drawn in the rectangular and square formats over a object as per the dimensions. This is also known as 2D bounding box annotation which also slightly shaded when drawn over a object, making easier for computers to recognize such objects and help machines to learn from such annotated data sets.
Whereas, in 3D image annotation the third-dimension is drawn using the lines to highlight the other conception of an object for more precise perception. It is also known as 3D bounding box annotation or 3D cuboid annotation needs extra time and efforts to annotate but more helpful in machine learning training mainly for indoor objects or other vehicle perception on road.
2D for Object Localization vs 3D for Spatial Cognition
In self-driving cars or autonomous driving 2D annotated images are used to localize the objects like pedestrians, lane obstacles, traffic signs and sign boards etc. While 3D annotation is to train the computer vision models for spatial perception from 2D images or videos to measure the relative distance object from the car and range can be measured making easier for self-driving cars to detect other cars and similar objects running on the road.
Use Cases of 2D and 3D Image Annotations
Basically, 2D image annotations are used for object localization in autonomous driving, object detection for ecommerce or retail industry, and damage detection for insurance claim and drone or robotics training for various sectors.
While on the other hand, 3D image annotation is used in precise distribution of various indoor objects and also in robotics training for autonomous warehousing and inventory management. 3D image annotation can be done using the 3D point cloud annotation and 3D cuboid annotation as per the perception model training data requirements.
How to get 2D and 3D Annotated Images?
I think you got certain idea what is the basic difference between 3D and 3D image annotations. And if you are looking to get such annotated images for your machine learning or AI project development, you can get the high-quality training data for machine learning and AI model training at most affordable cost with flexible pricing.





Leave a comment